【IT】<Twitter>凍結したアカウントにて、リストのユーザーIDを復旧してみた。~REST API/正規表現~
導入・趣旨
「凍結されちまった悲しみに・・・」
どうも芦原中也です。
さてね。

さる2018年8月9日、仕事で多忙を極めてる間に、
ツイッターアカウント(@mara_ashida)がいつの間にか凍結されてたワロス・・・
どうやら、Twitter社によるホロコーストが行われた模様で草
芦田マラのような、良識あふれる、平和な聖人アカウントを凍結する、Twitter社の目は節穴!はっきり言ってバカ!
というわけでアカウントを復活させるためにも、凍結アカウントにログインしてみたのですが、フォローしてた人をトレースできない・・・・

本エントリでは、フォローしてた人は諦めて、とりあえず、リスト管理してた人のデータを復旧する手順を掲載します。
<前提>
・PC環境があること
・ChromeがInstallされていること
・サクラエディタなどのフリーのテキストエディタソフトがInstallされていること
<ターゲット>
・テキストエディタの基本的な操作が行えること
・ツイッターアカウントが凍結された愚か者だが、リストを普段活用していた救いのある者
・非エンジニアでも、ある程度ITリテラシーがある人
目次・流れ
| No | タイトル |
|---|---|
| 1 | 【手順】HTMLのデータをテキストとして取得する |
| 2 | 【手順】ユーザIDの抽出(Grep)とデータの整形(置換)を行う |
| 3 | 解説・補足 |
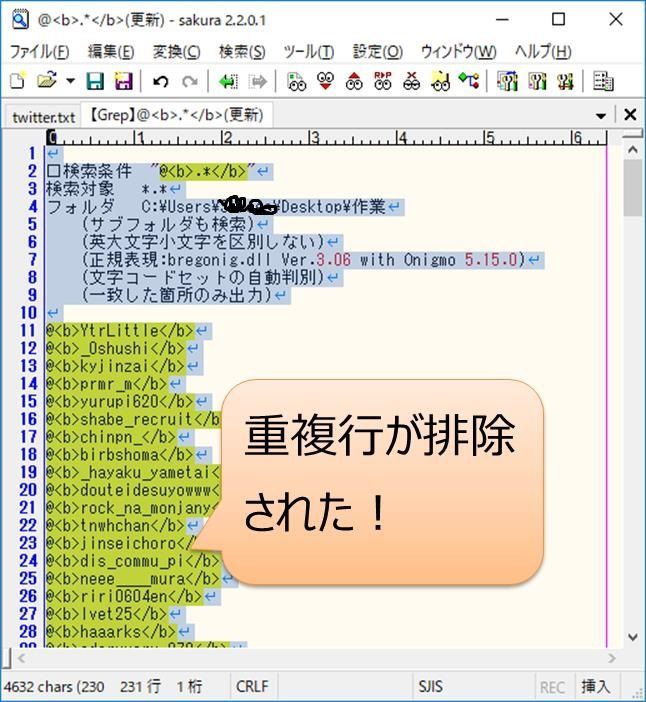
私は15分かからずリストのデータを復旧しました!
※JavaScriptを使用した抽出方法も3.解説・補足に記載してます(こっちのほうが楽かも)。
1.【手順】HTMLのデータをテキストとして取得する
ざっくり言うと、まずはHTMLのタグごとデータを取得し、Textファイルに保存します。
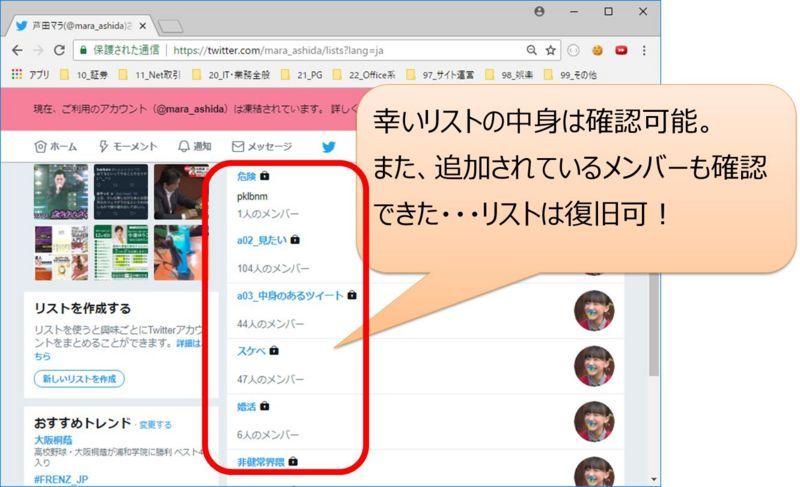
【操作】凍結したTwitterアカウントにログイン>画面右上 アイコン押下>リストメニュー押下
【確認内容】リスト画面に遷移すること
【操作】復旧したいリストのリンク押下>「リストに追加されているユーザー」押下
【確認内容】リストユーザー一覧画面(以下「対象画面」)に遷移すること
【確認内容】リスト画面に遷移すること
【操作】復旧したいリストのリンク押下>「リストに追加されているユーザー」押下
【確認内容】リストユーザー一覧画面(以下「対象画面」)に遷移すること

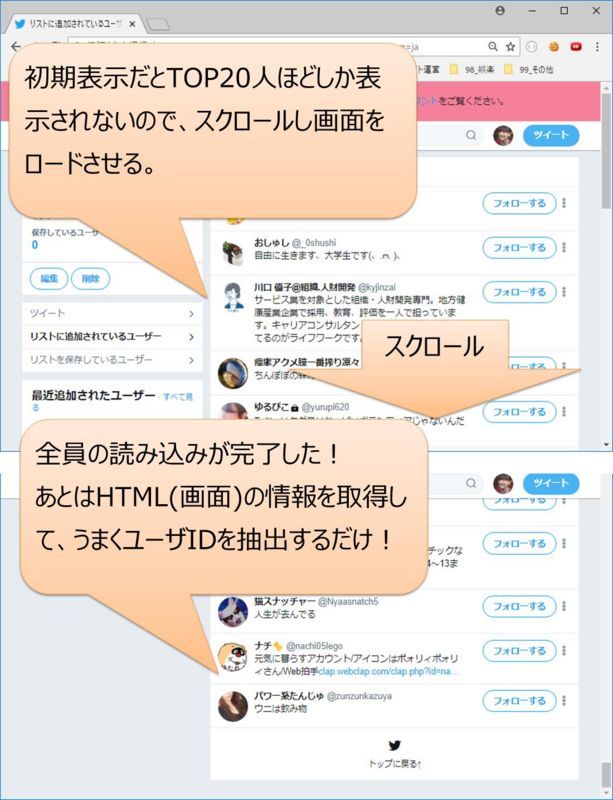
【操作】初期表示画面にて、スクロールバーを下にスライドし続ける/マウスホイールでスライド/ENDキーを連続押下
【確認内容】対象画面にて、読み込みが完了し、リストに追加されている全てのユーザが表示されること
【確認内容】対象画面にて、読み込みが完了し、リストに追加されている全てのユーザが表示されること

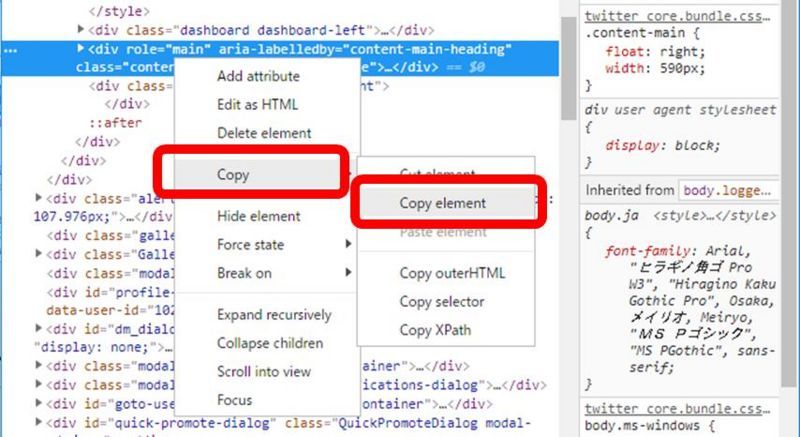
【操作】対象画面にてF12キー押下>「Elements」タブを押下
【確認内容】Chromeに付属しているデベロッパーツールが起動すること
【操作】対象画面にてCtrl+Shift+Cキー押下(Elementの選択モードになる)>対象画面の取得したいエリアをクリックし選択
【確認内容】対象画面の取得したいElementを特定できること
【確認内容】Chromeに付属しているデベロッパーツールが起動すること
【操作】対象画面にてCtrl+Shift+Cキー押下(Elementの選択モードになる)>対象画面の取得したいエリアをクリックし選択
【確認内容】対象画面の取得したいElementを特定できること
※参考:https://saruwakakun.com/html-css/basic/chrome-dev-tool


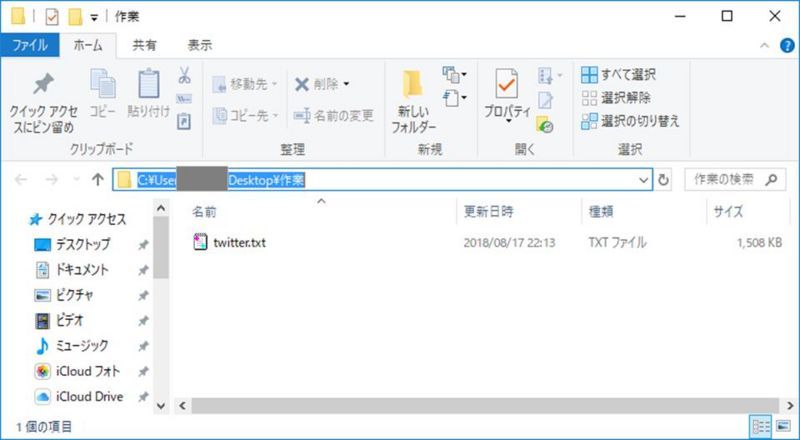
【操作】いったんTextファイルを保存。Grep(テキストファイルから文字列を検索する)を行うため、保存したファイルを任意のフォルダに移動する
2.【手順】ユーザIDの抽出(Grep)とデータの整形(置換)を行う
ざっくり言うと、ID情報だけ抽出して、余計な文字を削除したらできあがり!

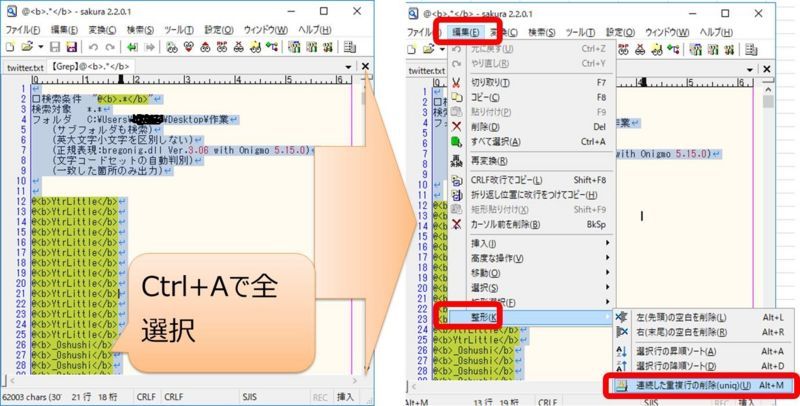
【操作】取得したい文字列(ID)を選択するため、Ctrl+Fキーで検索ダイアログを表示し、下記の通り検索条件を設定>検索押下
条件:「@<b>.*</b>」 ※3.解説参照
正規表現:チェック
【確認内容】「@<b>XXXXXXX</b>」の箇所のみ選択されること
条件:「@<b>.*</b>」 ※3.解説参照
正規表現:チェック
【確認内容】「@<b>XXXXXXX</b>」の箇所のみ選択されること


【操作】取得したい文字列(ID)を抽出するため、Ctrl+GキーでGrepダイアログを表示し、下記の通り検索条件を設定>検索押下
条件:「@<b>.*</b>」
フォルダ:本テキストファイルが格納されているフォルダ
正規表現:チェック
結果出力:該当部分
結果出力形式:結果のみ
【確認内容】「@<b>XXXXXXX</b>」の箇所のみ抽出されること
条件:「@<b>.*</b>」
フォルダ:本テキストファイルが格納されているフォルダ
正規表現:チェック
結果出力:該当部分
結果出力形式:結果のみ
【確認内容】「@<b>XXXXXXX</b>」の箇所のみ抽出されること


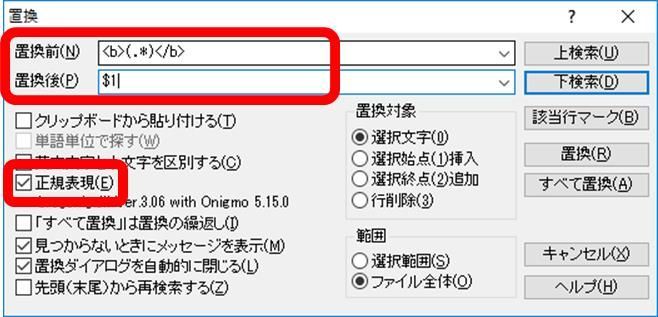
【操作】不要な文字列(<b>など)を削除するため、Alt+S+Rキーで置換ダイアログを表示し、下記の通り検索条件を設定>「すべて置換」押下
置換前:「<b>(.*)</b>」
置換後:「$1」 ※3.解説参照
正規表現:チェック
【確認内容】不要な文字列が削除されていること
置換前:「<b>(.*)</b>」
置換後:「$1」 ※3.解説参照
正規表現:チェック
【確認内容】不要な文字列が削除されていること

3.解説・補足
- 【REST API】右クリック>ページのソースを表示でHTML上、ユーザデータが取得できなかった理由
TwitterではREST APIというAPIを使用しており、
ざっくりいうと、Twitterのサービスにアクセスする際、
Webサーバは最低限の(静的な)HTMLテンプレートしか返さず、実際のデータはJSON・XML形式で返し、JavaScriptで画面を描画している。
つまり、(静的な)HTMLを常にサーバから返し画面のリフレッシュを行うのではなく、
サーバはJSON・XMLデータのみ返し、クライアント側のJavaScriptでデータを整形し描画する。
そうすることで、リアルタイムなタイムラインの更新が行える。
今回は、HTMLのテンプレートしか表示されなかったため、実際のユーザIDを視認することができなかったというわけである。
参考:https://qiita.com/masato44gm/items/dffb8281536ad321fb08
※実際にサーバからレスポンスされたJSONファイルの中身を確認すると「data-screen-name」というパラメータにユーザIDが設定されていたので、JSONファイルを取得して、そこから抽出することもできるが、抽出作業が少しめんどそうだったので今回は触れない。
ざっくりいうと、Twitterのサービスにアクセスする際、
Webサーバは最低限の(静的な)HTMLテンプレートしか返さず、実際のデータはJSON・XML形式で返し、JavaScriptで画面を描画している。
つまり、(静的な)HTMLを常にサーバから返し画面のリフレッシュを行うのではなく、
サーバはJSON・XMLデータのみ返し、クライアント側のJavaScriptでデータを整形し描画する。
そうすることで、リアルタイムなタイムラインの更新が行える。
今回は、HTMLのテンプレートしか表示されなかったため、実際のユーザIDを視認することができなかったというわけである。
参考:https://qiita.com/masato44gm/items/dffb8281536ad321fb08
※実際にサーバからレスポンスされたJSONファイルの中身を確認すると「data-screen-name」というパラメータにユーザIDが設定されていたので、JSONファイルを取得して、そこから抽出することもできるが、抽出作業が少しめんどそうだったので今回は触れない。
/*【参考】JavaScriptを使用した取得方法 ・機能:JavaScriptの下記コードを実行すると、不足なく取得できました。 ・実行場所:ユーザリスト画面でLOADを完了した状態で、Chrome>F12キー>Consoleタブ にて下記コードを張り付けて、Enterキーで実行。 */ var work var result var x = document.getElementById("stream-items-id").children; for(var i = 0; i < x.length; ++i){ work = '@'+ x[i].getElementsByTagName("div")[0]. getAttribute("data-screen-name")+ '\r\n'; result = result + work; } /*補足 ・stream-items-id配下がフォロワーのユーザLISTになっている。LISTの長さ分だけLOOPしてユーザIDを取得する。 ・data-screen-nameという属性にユーザIDが設定されているので、それを取得するという処理。 ・値が上書きされないように、workをresultに代入している。 */
- 【正規表現】検索・抽出・置換の文字列の意味
・「@<b>.*</b>」:検索したいのは「@<b>UserID</b>」だったが、「UserID」は可変の項目なので、一括指定するには工夫が必要。ここでは、正規表現という指定方法を活用し、可変項目を一括指定している。
「UserID」に相当するのは「.*」の箇所。「.」は「任意の1文字」、「*」は「前の文字の連続」という意味。
こうすることで、「<b>」と「</b>」に囲まれた「UserID」を一括指定できる。
・「<b>(.*)</b>」「$1」:不要な文字列(「<b>」と「</b>」)を削除する際、不思議な文字列を記載しているのがお分かりか?
置換前に「.*」と指定しているのは、上記の説明と同じ。「()」の意味は、置換後の指定でも ()で囲まれた箇所をそのまま使いますよ という意味。
置換後に「$1」と指定しているのは、「()」で囲まれた文字(置換前に保存した領域)を参照している。つまり、置換前に指定した「(.*)」の箇所を、置換後の結果に入れていることに他ならない。
「UserID」に相当するのは「.*」の箇所。「.」は「任意の1文字」、「*」は「前の文字の連続」という意味。
こうすることで、「<b>」と「</b>」に囲まれた「UserID」を一括指定できる。
・「<b>(.*)</b>」「$1」:不要な文字列(「<b>」と「</b>」)を削除する際、不思議な文字列を記載しているのがお分かりか?
置換前に「.*」と指定しているのは、上記の説明と同じ。「()」の意味は、置換後の指定でも ()で囲まれた箇所をそのまま使いますよ という意味。
置換後に「$1」と指定しているのは、「()」で囲まれた文字(置換前に保存した領域)を参照している。つまり、置換前に指定した「(.*)」の箇所を、置換後の結果に入れていることに他ならない。
以上。